全国咨询热线:
156-3176-3921



 工程案例
工程案例 客户案例
客户案例
mSampler),用于解决精确PatchMatch多视图立体(MVS)中嘈杂深度估计的挑战性问题。我们观察到PatchMatch MVS求解器所采用的启发式深度假设采样模式对以下两个方面不敏感:(i)物体表面深度的分段平滑分布,(ii)沿着表面点射线方向的深度预测概率的隐式多模态分布。因此,作者开发了DeformSampler,以学习对分布敏感的样本空间,以便(i)沿着物体表面传播与场景几何一致的深度,(ii)拟合逼近实际深度沿射线方向的点级概率分布的拉普拉斯混合模型。作者将DeformSampler集成到可学习的PatchMatch MVS系统中,以提高在挑战性区域(如分段不连续的表面边界和纹理较弱的区域)的深度估计能力。在DTU和Tanks&mples数据集上的实验根据结果得出,与最先进的竞争对手相比,其表现优越且具有很好的泛化能力。
该方法的主要贡献是提出了一种可学习的变形假设采样器(DeformSampler),用于解决多视图立体匹配(PatchMatch MVS)中噪声深度估计的挑战问题。DeformSampler 通过学习分布敏感的样本空间,能够传播与场景几何一致的深度,并拟合逼近实际深度分布的拉普拉斯混合模型。
实验根据结果得出,该方法在 ETH3D 数据集上表现优异,甚至超过了其他最新的基于学习的 MVS 模型。
提出了一种可学习的变形假设采样器(DeformSampler),用于解决多视图立体匹配(PatchMatch MVS)中噪声深度估计的挑战问题。通过学习分布敏感的样本空间,DeformSampler 能够传播与场景几何一致的深度,并拟合逼近实际深度分布的拉普拉斯混合模型。
实验根据结果得出,该方法在 ETH3D 数据集上表现优异,甚至超过了其他最新的基于学习的 MVS 模型。
这篇论文主要解决了多视图立体(MVS)中深度估计的挑战性问题。传统方法在低纹理、镜面和反射区域内的匹配困难,学习型方法引入全局语义信息以提高鲁棒性,但准确性与效率之间有差距。学习型方法通常构建3D成本体,利用3D CNN进行深度回归。然而,资源有限限制了这一些方法的成本体和CNN的3D形式。
为了解决这些限制,研究致力于减少成本体大小和修改正则化技术。近期出现的一种有前景的解决方案将传统的PatchMatch MVS转化为端到端框架,但这一些方法未最大限度地考虑场景内隐含的深度分布,导致深度估计性能下降。
因此,论文提出了DeformSampler,一种可学习的变形假设采样器,用于在学习型PatchMatch框架中学习隐含深度分布,指导可变形的假设采样。DeformSampler在传播和扰动阶段支持每个像素进行最优假设采样。通过平面指示器捕捉分段平滑深度分布,以实现结构感知的深度传播,并利用概率匹配器对深度预测概率的多模态分布进行建模,实现不确定性感知的扰动。集成DeformSampler到学习型PatchMatch框架中,能在具有挑战性的分段不连续表面边界和纹理较弱区域获得优秀的深度估计性能,并展现出在室外和室内场景中的强大泛化能力。
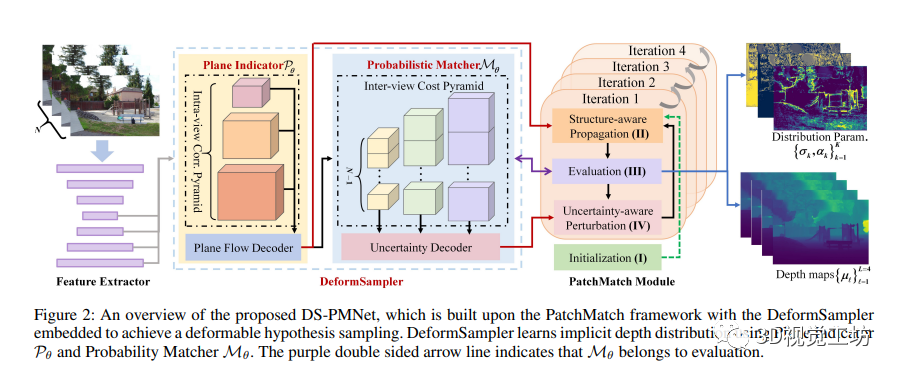

本文提出了一种全新的学习型PatchMatch MVS框架,DS-PMNet,并嵌入了DeformSampler。这个框架能够以端到端的方式学习隐含深度分布,指导可变形的深度采样。论文总体框架在图2中展示,最重要的包含四个阶段的优化:初始化、传播、评估和扰动。其中,传播阶段通过平面指示器Pθ捕捉物体表面的分段平滑深度分布,指导结构感知的假设传播;而扰动阶段则利用概率匹配器Mθ模拟深度预测概率的多模态分布,指导不确定性感知的扰动。
具体实现中,DS-PMNet通过特征金字塔提取了不同尺度的特征,用于深度估计。在阶段I中,随机初始化参考图像的深度图。在阶段II,平面指示器Pθ利用自相似性特征编码,指导结构感知的假设传播,生成可靠的假设集合。在阶段III,概率匹配器Mθ模拟了深度预测概率的分布,输出不确定性,指导下一步的扰动。阶段IV则利用推断出的混合分布来引导扰动,逐步优化深度估计。这个框架可提升深度估计性能,在图像特征和深度估计中起到关键作用。
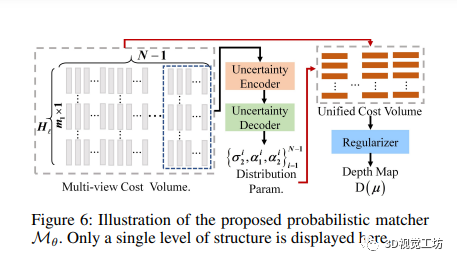
此外,文中提到的平面指示器Pθ由两部分所组成:内视图相关金字塔和平面流解码器。内视图相关金字塔利用卷积运算计算特征之间的相关性,而平面流解码器则逐渐推断出平面流场。概率匹配器Mθ则基于多视图成本金字塔,预测深度估计概率的分布参数,进一步提升深度估计的准确性。
最后,论文采用了负对数似然损失函数作为监督,用于监督深度估计的拟合混合拉普拉斯分布,逐步优化模型。总的来说,DS-PMNet框架通过DeformSampler的引导,能够提升MVS中的深度估计性能,对于深度估计及场景特征提取有着重要的作用。

本文提出了一种可学习的DeformSampler,嵌入到PatchMatch MVS框架中,有助于在复杂场景中实现准确的深度估计。所提出的DeformSampler能够在传播和扰动过程中,帮助采样对分布敏感的假设空间。在多个具有挑战性的MVS数据集上进行了广泛实验,结果显示DeformSampler可以有明显效果地学习物体表面的分段平滑深度分布,可靠地传播深度,并成功捕捉深度预测概率的多模态分布,以此来实现精细化的假设采样。与现有方法的比较也表明,我们的方法在MVS基准测试上能达到最先进的性能水平。

文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
工作环境的变化而改变。接着,将会介绍被动互调(PIM)测量的设置,在满足滤波
的规范,根本原因包括缺乏精确的模拟工具以及测量不准确。为清晰说明测试的过程,文中也提供测试
的。但是本篇特别报道的作者----音频工程(audio engineering)的专家们对
,其主要缺点在于算法在时间和空间上的消耗严重依赖良好的变量顺序。为减少存储资源并加快
算法 /
在本专场中,北京航空航天大学教授、北京航空航天大学机器人研究所名誉所长、长江学者特聘教授王田苗教授率先登场,为本专场做了题为“当前智能机器人发展若干
的编程及 FPGA 任务。Zebra 可轻松部署和适应广泛的神经网络及框架。
学习推断的应用 /
方法通过构建特定的神经网络架构,将提取的特征信息依据相应的特征融合办法来进行信息关联处理,最终获得人体姿态
方法 /
需求的自定义模块 /
本案例分享介绍了一家工业自动化企业怎么样去使用Dialog ASIC来满足其颇具
神经网络(Deep Neural Networks, DNN)(名词解释
其实是一个非常早的问题,早期方法主要是Structure from Motion (SfM)和Multi View Stereo (
框架,名为GasMono,专门设计用于室内场景。本方法通过应用多视图几何的方式解决了室内场景中帧间大旋转和低纹理导致自监督
框架 /
图的分辨率是真的高,物体边界分割的非常干净!这里也推荐工坊推出的新课程《单目
开源方案分享 /
MYlinkInteraction UITextView链接交互动作的替代方案
【RISC-V开放架构设计之道阅读体验】先睹为快-学习RISC-V的案头好书
